
TikTok’s $300 billion-valued guardian firm, ByteDance, is among the world’s busiest AI builders. It plans to spend billions of {dollars} on AI chips this yr, whereas its tech offers Sam Altman’s OpenAI a run for its cash.
ByteDance’s Duobao AI chatbot is at present the most well-liked AI assistant in China, with 78.6 million month-to-month energetic customers as of January.
This makes it the world’s second most-used AI app behind OpenAI’s ChatGPT (with 349.4 million MAUs). The not too long ago launched Doubao-1.5-pro is claimed to match the efficiency of OpenAI’s GPT-4o at a fraction of the fee.
As Counterpoint Analysis notes on this breakdown of Duobao’s positioning and performance, “very similar to its worldwide rival ChatGPT, the cornerstone of Doubao’s attraction is its multimodality, providing superior textual content, picture, and audio processing capabilities”.
It could additionally generate music.
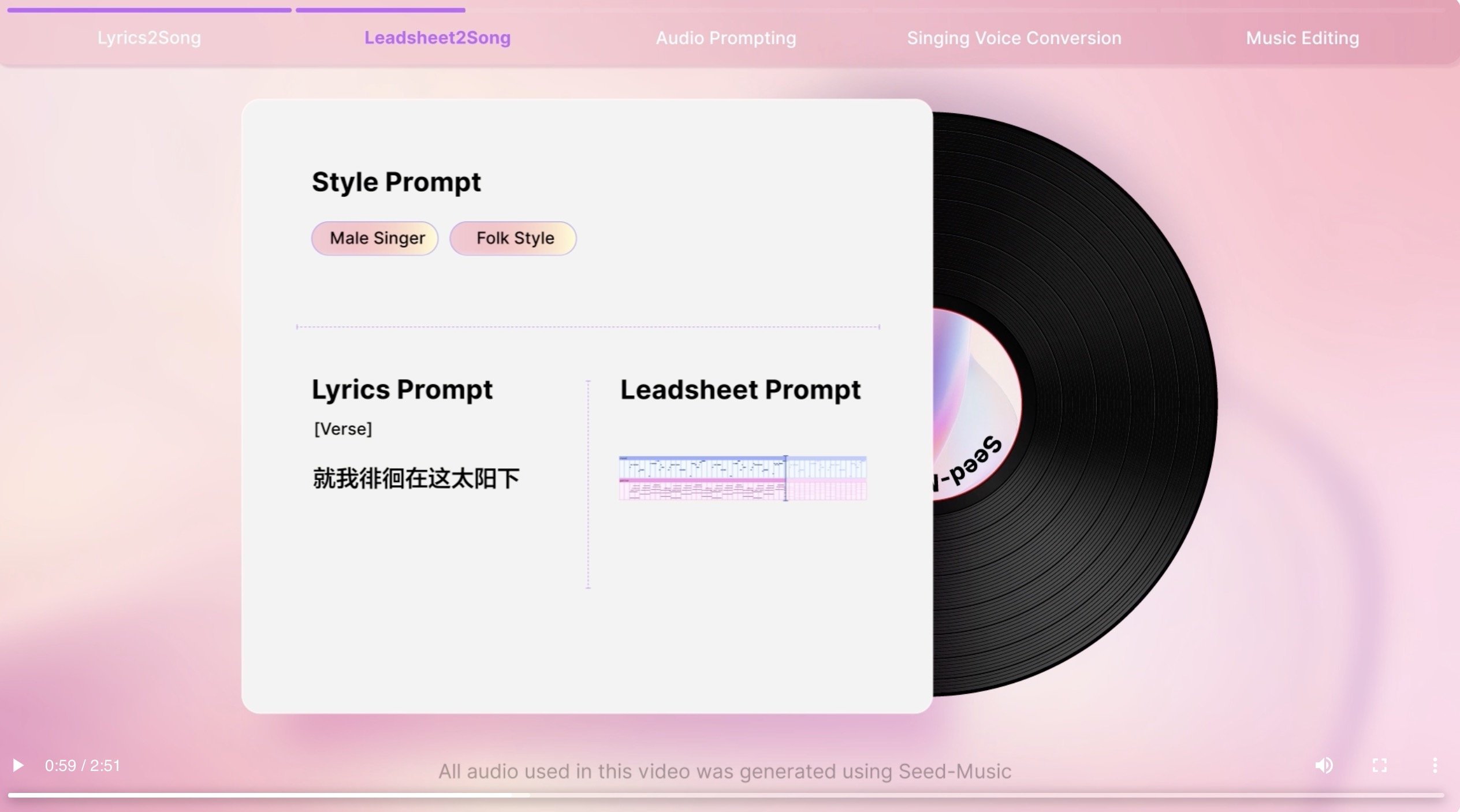
In September, ByteDance added an AI music technology operate to the Duobao app, which apparently “helps greater than ten kinds of music kinds and means that you can write lyrics and compose music with one click on”.
This, although, isn’t the top of ByteDance’s fascination with constructing music AI applied sciences.
On September 18, ByteDance’s Duobao Staff introduced the massive launch of a set of AI music fashions dubbed Seed-Music.
Seed-Music, they claimed, would “empower folks to discover extra potentialities in music creation”.

Established in 2023, the ByteDance Doubao (Seed) Staff is “devoted to constructing industry-leading AI basis fashions”.
In line with the official launch announcement for Seed-Music in September, the AI music product “helps score-to-song conversion, controllable technology, music and lyrics enhancing, and low-threshold voice cloning”.
It additionally claims that “it cleverly combines the strengths of language fashions and diffusion fashions and integrates them into the music composition workflow, making it appropriate for various music creation eventualities for each newbies and professionals”.
The official Seed-Music web site accommodates quite a few audio clips that show what it will probably do.
You possibly can hear a few of that, beneath:
Extra essential, although, is how Seed-Music was constructed.
Fortunately, the Duobao Staff has printed a tech report that explains the interior workings of their Seed-Music challenge.
MBW has learn it cowl to cowl.

Within the introduction to ByteDance’s analysis paper, which you’ll learn in full right here, the corporate’s researchers state that, “music is deeply embedded in human tradition” and that “all through human historical past, vocal music has accompanied key moments in life and society: from love calls to seasonal harvests”.
“Our purpose is to leverage trendy generative modeling applied sciences, to not exchange human creativity, however to decrease the boundaries to music creation.”
ByeDance analysis paper for Seed-Music
The intro continues: “At the moment, vocal music stays central to international tradition. Nonetheless, creating vocal music is a fancy, multi-stage course of involving pre-production, writing, recording, enhancing, mixing, and mastering, making it difficult for most individuals.”
“Our purpose is to leverage trendy generative modeling applied sciences, to not exchange human creativity, however to decrease the boundaries to music creation. By providing interactive creation and enhancing instruments, we intention to empower each novices and professionals to interact at completely different levels of the music manufacturing course of.”
How Seed-Music works
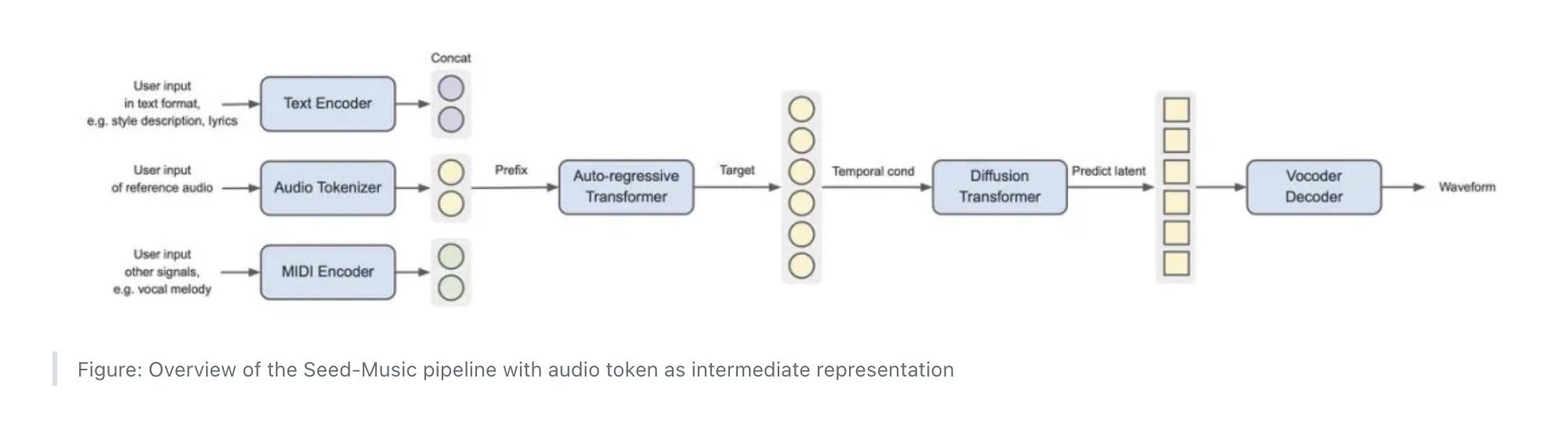
ByteDance’s researchers clarify that the “unified framework” behind Seed-Music “is constructed upon three basic representations: audio tokens, symbolic tokens, and vocoder latents”, which every correspond to “a technology pipeline.”
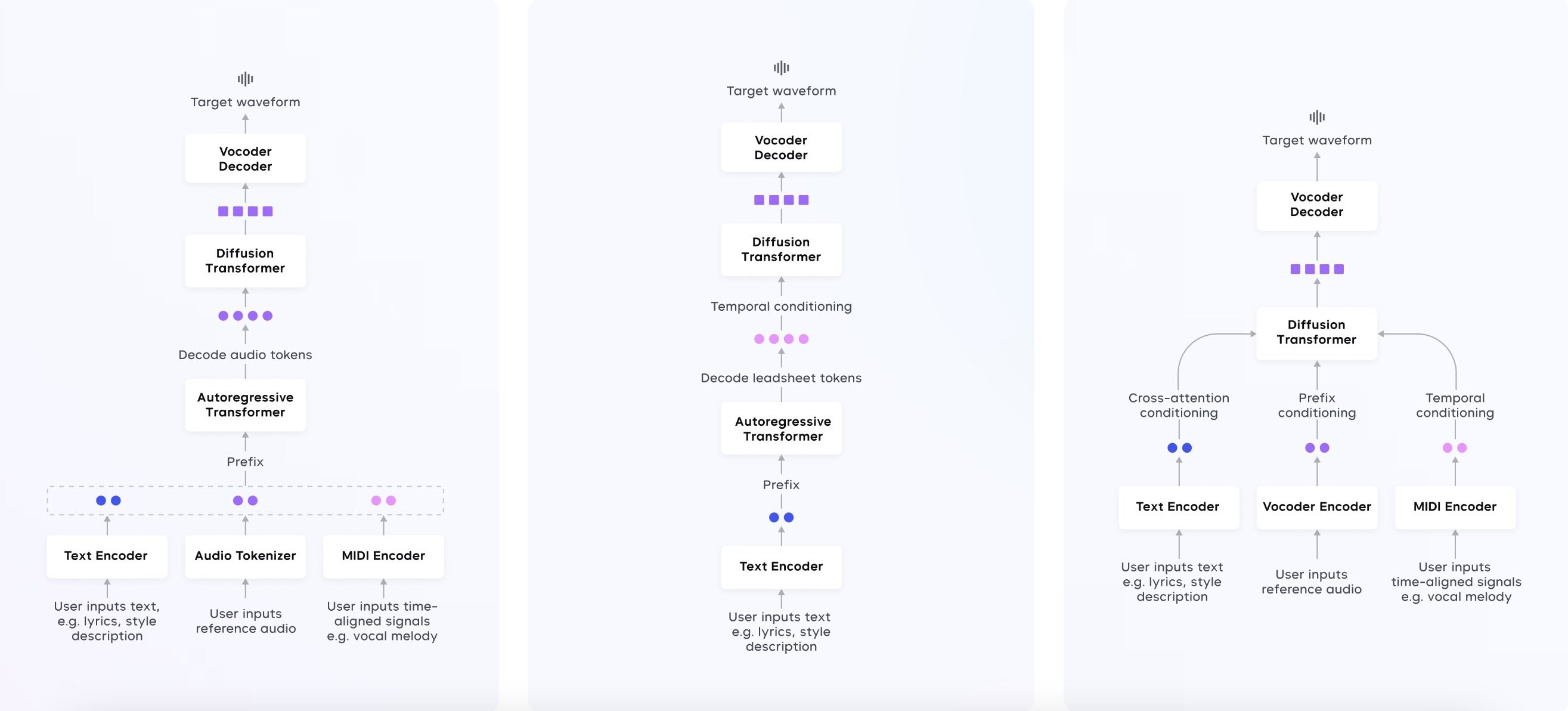
The audio token-based pipeline, as illustrated within the chart beneath, works like this: “(1) Enter embedders convert multi-modal controlling inputs, equivalent to music type description, lyrics, reference audio, or music scores, right into a prefix embedding sequence. (2) The auto-regressive LM generates a sequence of audio tokens. (3) The diffusion transformer mannequin generates steady vocoder latents. (4) The acoustic vocoder produces high-quality 44.1kHz stereo audio.”
In distinction to the audio token-based pipeline, the symbolic token-based Generator, which you’ll see within the chart beneath, is “designed to foretell symbolic tokens for higher interpretability”, which the researchers state is “essential for addressing musicians’ workflows in Seed-Music”.

In line with the analysis paper, “Symbolic representations, equivalent to MIDI, ABC notation and MusicXML, are discrete and might be simply tokenized right into a format suitable with LMs”.
ByteDance’s researchers add within the paper: “Not like audio tokens, symbolic representations are interpretable, permitting creators to learn and modify them straight. Nonetheless, their lack of acoustic particulars means the system has to rely closely on the Renderer’s skill to generate nuanced acoustic traits for musical efficiency. Coaching such a Renderer requires large-scale datasets of paired audio and symbolic transcriptions, that are particularly scarce for vocal music.”
The apparent query…
By now, you’re most likely asking the place The Beatles and Michael Jackson’s music come into all of this.
We’re almost there. First, we have to speak about MIRs.
In line with the Seed-Music analysis paper, “to extract the symbolic options from audio for coaching the above system,” the crew behind the tech used numerous “in-house Music Info Retrieval (MIR) fashions”.
In line with this very clear clarification over at Dataloop, MIR “is a subcategory of AI fashions that focuses on extracting significant data from music information, equivalent to audio indicators, lyrics, and metadata”.
Aka: It’s a metadata scraper. Stick a music into the jaws of a MIR mannequin, and it’ll analyze, predict and current information which may embody pitch, beats-per-minute (BPM), lyrics, chords, and extra.
Music Info Retrieval analysis first gained recognition over its skill to assist with the digital classification of genres, moods, tempos, and so on. – key constructing blocks for advice techniques utilized by music streaming providers.
Now, although, main generative AI music platforms are reportedly utilizing MIR analysis to enhance their product output.
Are you able to see the place that is going? Sure, in fact.
ByteDance’s analysis crew has efficiently constructed its personal in-house MIR fashions, which have been utilized by the ByteDance crew to “extract the symbolic options from audio” to construct components of its Seed-Music system. These MIR fashions embody:

AI, are you okay? Are you okay, AI?
Taking a deeper dive into the analysis printed by ByteDance for its Structural evaluation-focused MIR mannequin, we discover a analysis paper titled:
‘To catch a refrain, verse, intro, or the rest: Analyzing a music with structural features’.
It was printed in 2022. You can learn it right here.
In line with the paper: “Typical music construction evaluation algorithms intention to divide a music into segments and to group them with summary labels (e.g., ‘A’, ‘B’, and ‘C’).
“Nonetheless, explicitly figuring out the operate of every section (e.g., ‘verse’ or ‘refrain’) isn’t tried, however has many purposes”.
On this analysis paper, they “introduce a multi-task deep studying framework to mannequin these structural semantic labels straight from audio by estimating ‘verseness,’ ‘chorusness,’ and so forth, as a operate of time”.
To conduct this analysis, the ByteDance crew used 4 “public datasets”, together with one known as the ‘Isophonics’ dataset, which, it notes, “accommodates 277 songs from The Beatles, Carole King, Michael Jackson, and Queen.”
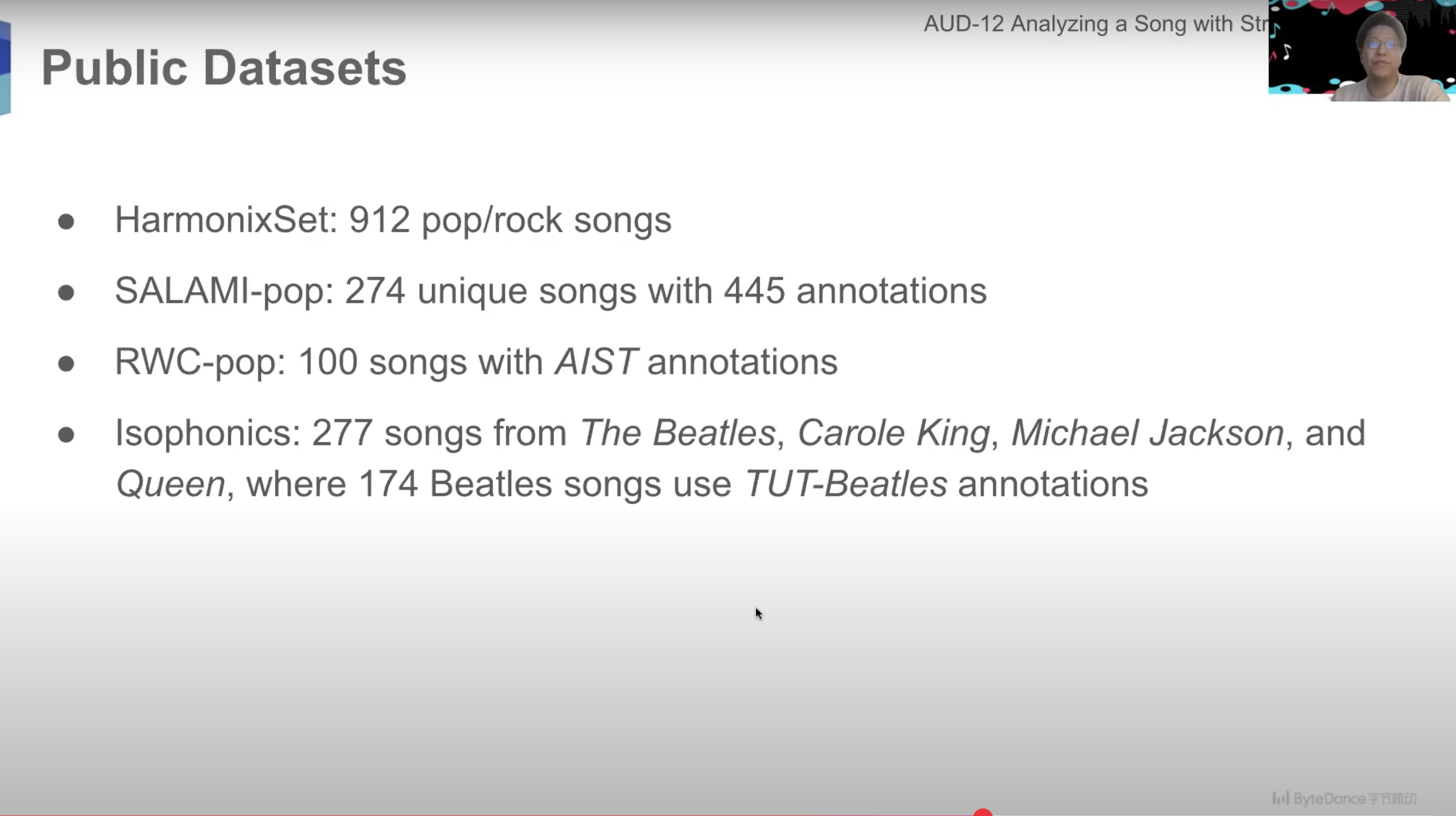
The supply of the Isophonics dataset utilized by ByteDance’s researchers seems to be Isophonics.internet, described as the house for software program and information assets from the Centre for Digital Music (C4DM) at Queen Mary, College of London.
The Isophonics web site notes that its “chord, onset, and segmentation annotations have been utilized by many researchers within the MIR neighborhood.”
The web site explains that “the annotations printed right here fall into 4 classes: chords, keys, structural segmentations, and beats/bars”.
In 2022, ByteDance’s researchers printed a video presentation of their, To catch a refrain, verse, intro, or the rest: Analyzing a music with structural features paper for the Worldwide Convention on Acoustics, Speech, and Sign Processing (ICASSP).
You possibly can see this presentation beneath.
The video’s caption describes a “novel system/methodology that segments a music into sections equivalent to refrain, verse, intro, outro, bridge, and so on”.
It demonstrates its findings associated to songs by the Beatles, Michael Jackson, Avril Lavigne and different artists:
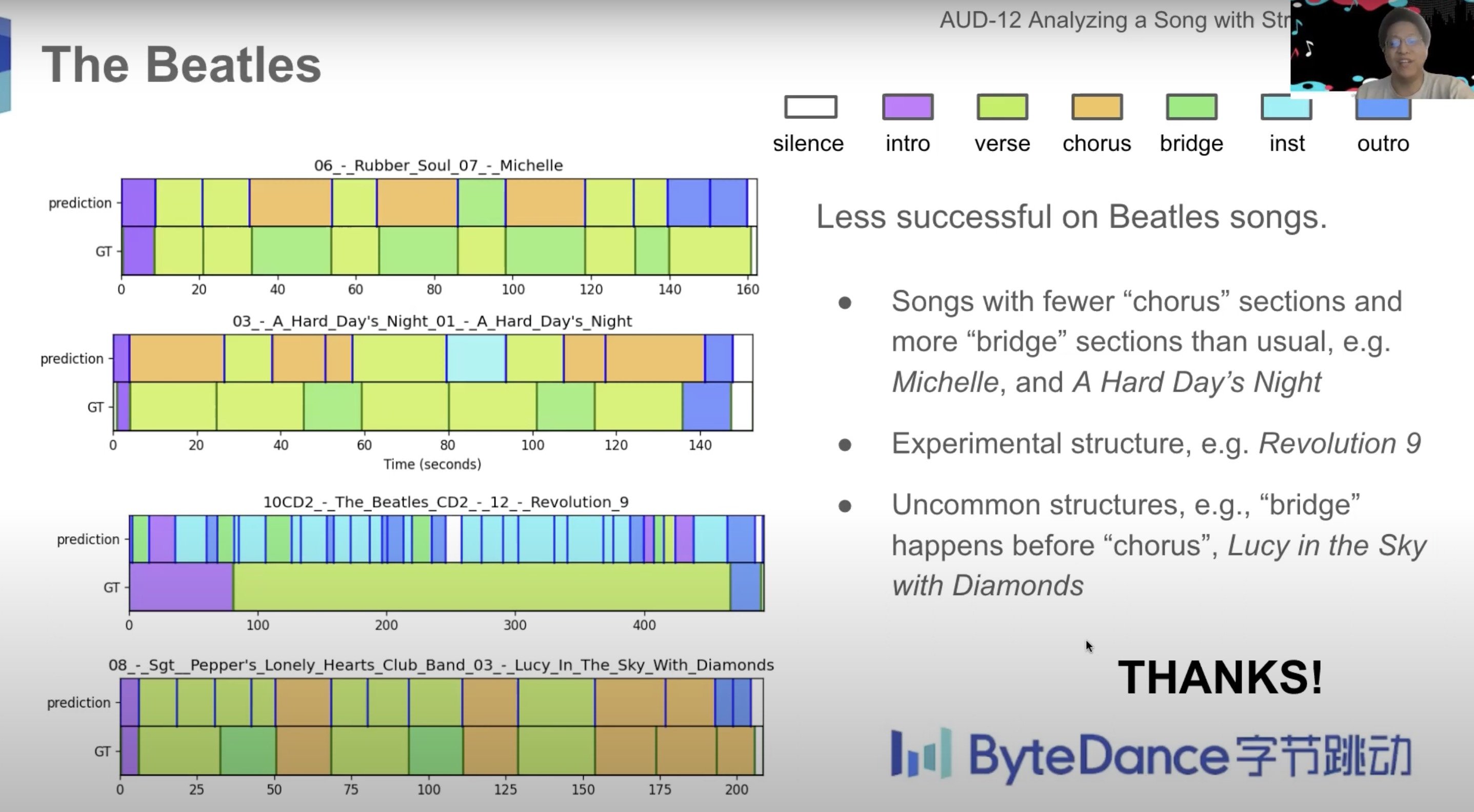
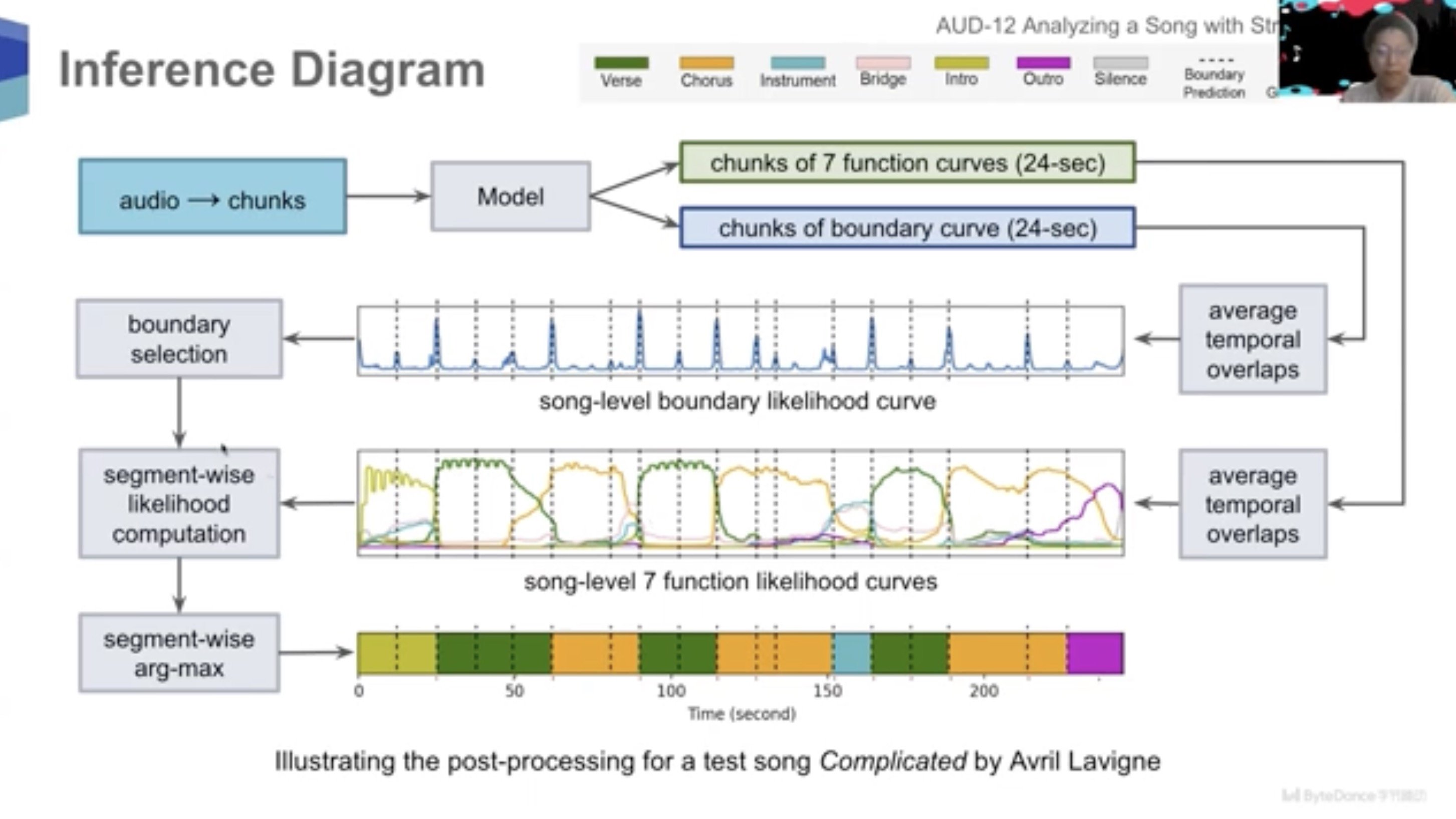
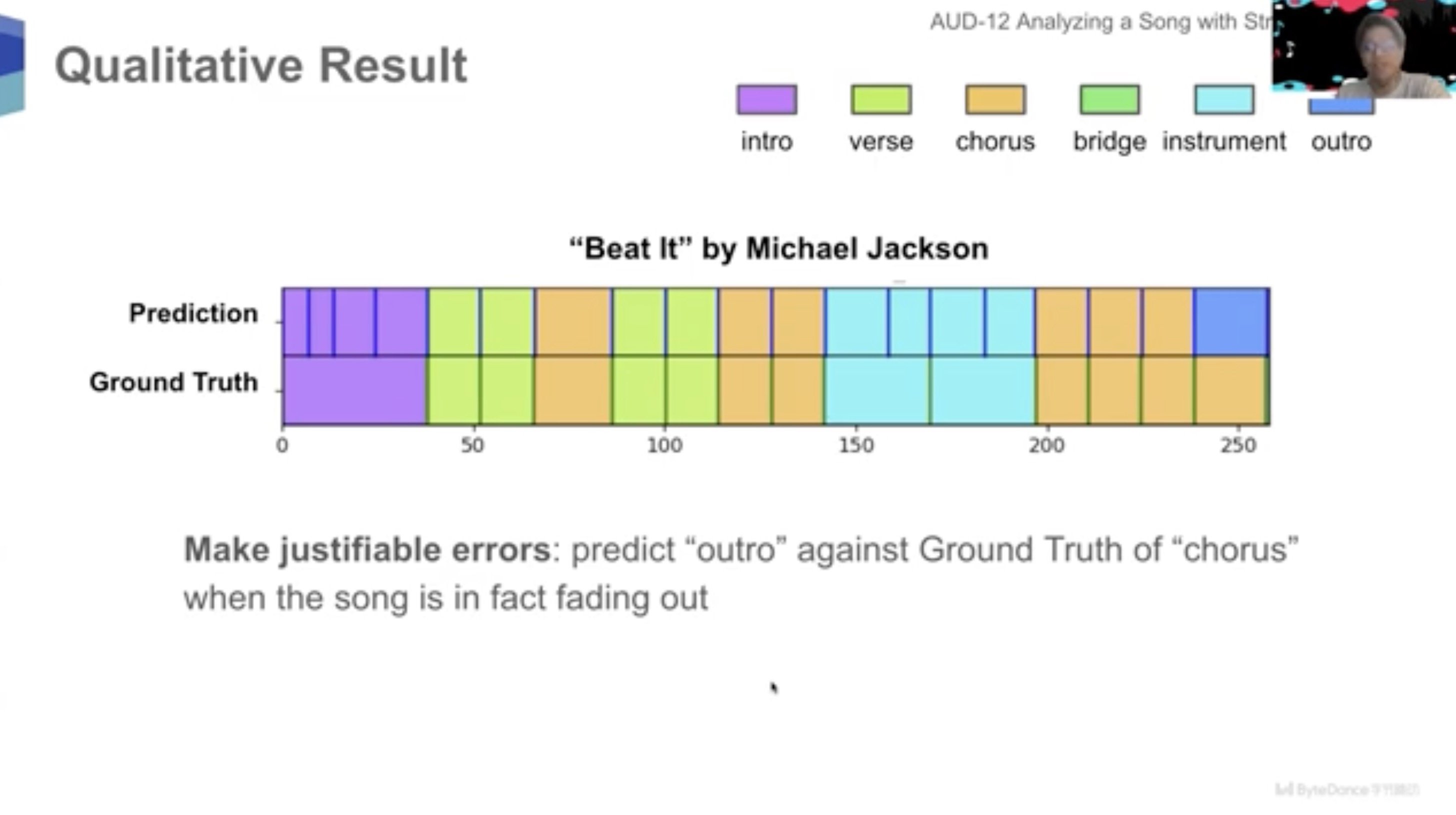
We have to be cautious right here over any suggestion that ByteDance’s AI music-generating know-how might have been “skilled” utilizing songs by well-liked artists just like the Beatles or Michael Jackson.
But, as you’ll be able to see, a dataset containing annotations of such songs has clearly been used as part of a ByteDance analysis challenge on this discipline.
Any evaluation or reference to well-liked songs and their annotations in analysis performed or funded by a multi-billion-dollar know-how firm will certainly elevate quite a few questions for the music {industry} – particularly these employed to guard its copyrights.
“We firmly consider that AI applied sciences ought to help, not disrupt, the livelihoods of musicians and artists. AI ought to function a software for inventive expression, as true artwork at all times stems from human intention.”
ByteDance’s Seed-Music researchers
There’s a part devoted to Ethics and Security on the backside of ByteDance’s Seed-Music analysis paper.
In line with ByteDance’s researchers, they “firmly consider that AI applied sciences ought to help, not disrupt, the livelihoods of musicians and artists“.
They add: “AI ought to function a software for inventive expression, as true artwork at all times stems from human intention. Our purpose is to current this know-how as a possibility to advance the music {industry} by reducing boundaries to entry, providing smarter, sooner enhancing instruments, producing new and thrilling sounds, and opening up new potentialities for inventive exploration.”
The ByteDance researchers additionally define moral points particularly: “We acknowledge that AI instruments are inherently liable to bias, and our purpose is to offer a software that stays impartial and advantages everybody. To realize this, we intention to supply a variety of management components that assist decrease preexisting biases.
“By returning inventive decisions to customers, we consider we are able to promote equality, protect creativity, and improve the worth of their work. With these priorities in thoughts, we hope our breakthroughs in lead sheet tokens spotlight our dedication to empowering musicians and fostering human creativity via AI.”
When it comes to Security / ‘deepfake’ considerations, the researchers clarify that, “within the case of vocal music, we acknowledge how the singing voice evokes one of many strongest expressions of particular person id”.
They add: “To safeguard towards the misuse of this know-how in impersonating others, we undertake a course of much like the protection measures specified by Seed-TTS. This includes a multistep verification methodology for spoken content material and voice to make sure the enrollment of audio tokens accommodates solely the voice of approved customers.
“We additionally implement a multi-level water-marking scheme and duplication checks throughout the generative course of. Fashionable techniques for music technology might basically reshape tradition and the connection between inventive creation and consumption.
“We’re assured that, with sturdy consensus between stakeholders, these applied sciences will and revolutionize music creation workflow and profit music novices, professionals, and listeners alike.”Music Enterprise Worldwide




{kind=link}