

Ahead-looking: Regardless of dealing with a setback within the rollout of its Blackwell GPUs for knowledge facilities final yr on account of a design flaw, Nvidia has swiftly rebounded and is poised to ship its subsequent sequence of merchandise over the subsequent few years. CEO Jensen Huang confirmed throughout the firm’s earnings name that the subsequent main launch, dubbed Blackwell Extremely (B300-series), is on observe for the second half of this yr.
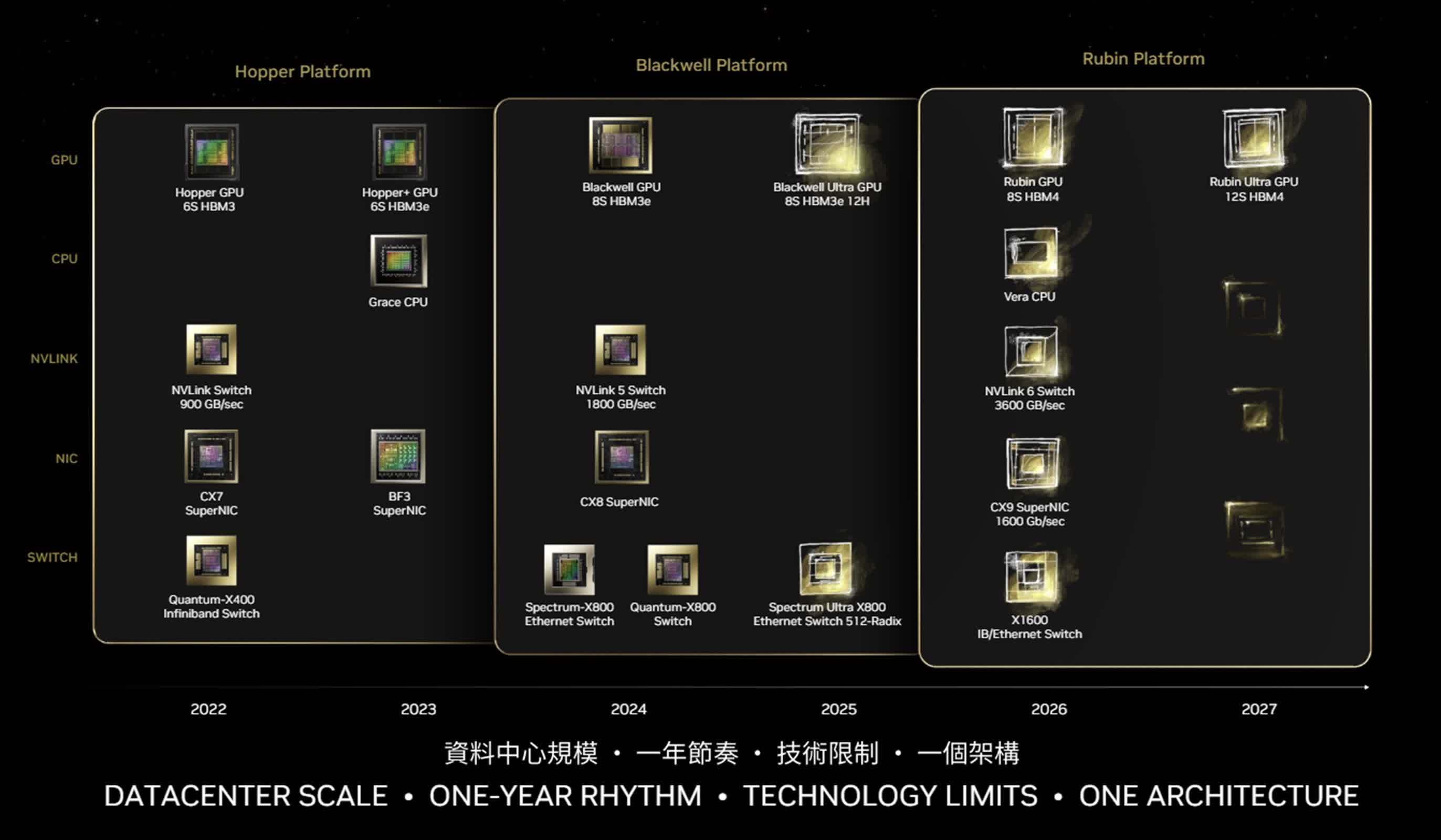
This mid-cycle refresh of the Blackwell structure guarantees vital enhancements over its predecessors. The B300-series is anticipated to supply increased compute efficiency and eight stacks of 12-Hello HBM3E reminiscence, offering as much as 288GB of onboard reminiscence. Though unofficial, there are estimates of a 50 % efficiency uplift in comparison with the B200-series.
To enhance these highly effective GPUs, Nvidia will introduce the Mellanox Spectrum Extremely X800 Ethernet change, boasting a radix of 512 and assist for as much as 512 ports. This networking improve will additional improve the capabilities of AI and HPC programs constructed across the B300-series.
Picture credit score: Constellation Analysis
Wanting past Blackwell, Nvidia is already engaged on its next-generation structure, codenamed Vera Rubin. Set to debut in 2026, the Rubin GPUs symbolize a major step towards attaining synthetic normal intelligence (AGI).
The Rubin platform will characteristic eight stacks of HBM4E reminiscence, providing as much as 288GB of reminiscence, together with a Vera CPU, NVLink 6 switches working at 3600 GB/s, CX9 community playing cards supporting 1,600 Gb/s, and X1600 switches. Huang has hinted on the transformative potential of the Rubin structure, describing it as a serious leap ahead when it comes to efficiency and capabilities.
Nvidia has additionally indicated its readiness to debate post-Rubin merchandise on the upcoming GPU Know-how Convention (GTC) in March. One potential breakthrough on the horizon is the rumored Rubin Extremely, projected for launch in 2027. This product might push the boundaries of GPU design even additional, probably incorporating 12 stacks of HBM4E reminiscence. It is a substantial improve from the 8 stacks utilized in earlier generations, probably providing as much as 576GB of complete reminiscence. The usage of HBM4E know-how would supply unprecedented reminiscence bandwidth and capability, essential for dealing with more and more advanced AI fashions and computations.
To realize this, Nvidia would wish to grasp the usage of 5.5-reticle-size CoWoS interposers and 100mm × 100mm substrates manufactured by TSMC. This represents a major improve from the present 3.3-reticle-size interposers utilized in at present’s most superior GPUs. The bigger interposer measurement would enable for extra parts to be built-in onto a single package deal, enabling the inclusion of further reminiscence stacks and probably extra GPU tiles.




{kind=link}